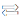Artificial intelligence chips mainly include NVidia GPU, Google's TPU, Intel's Nervana, IBM's TreueNorth, Microsoft's DPU and BrainWave, Baidu's XPU, Xilinx's xDNN, Cambrian chip, Horizon and Deepview's AI chip, etc. Basically, GPU, FPGA, and neural network chips are the three major trends. The three chips have their own advantages and disadvantages and are all geared towards their own unique market segments. This chapter first talks about the rise of deep neural networks and NVidia GPUs.
The ultimate goal of artificial intelligence is to simulate the human brain, which has roughly 100 billion neurons and 100 trillion synapses, capable of handling complex vision, hearing, smell, taste, language skills, comprehension, cognitive abilities, emotional control, control of complex body mechanisms, complex psychological and physiological control, while consuming only 10 to 20 watts of power.
These are the basic neurons and synapses of the human brain.
.jpg.jpg)
The inputs simulate electrical signals to neurons, the weights simulate synaptic connections between neurons, and the activation functions simulate electrical signal conduction between synapses.
As early as 1981 David Hubel and Torsten Wiesel discovered that information processing in the human visual system is hierarchical, and thus won the Nobel Prize in medicine. As shown in the figure, starting from the retina, through the low-level V1 area for edge feature extraction, to V2 area for recognizing basic shapes or localization of targets, to the high-level target recognition (e.g., recognizing faces), and to the higher-level prefrontal cortex for classification judgments, etc., it was realized that the high-level features are combinations of low-level features that become more and more abstract and express semantics or intentions from the lower to the higher levels.
Deep neural network models simulate the hierarchical recognition process of human brain recognition.
The input layer of deep neural network simulates the input of visual signal, different hidden layers simulate different levels of abstraction, and the output layer simulates the output of object classification or semantics, etc.
From the above typical face recognition training task, according to 10 layers of deep neural network, training millions of pictures, about 30 Exaflops of computing power is needed, if still using CPU to do training, it takes about a year of training time, which is obviously intolerable speed, the urgent need for artificial neural network chip with stronger computing power appears.
The Rise of NVidia GPUs
Many people may ask why NVidia GPU has an unshakable dominant position in the field of artificial intelligence, and why the performance of AMD GPU and NVidia GPU is similar, but there is a world of difference in the popularity of the field of artificial intelligence.
We know that GPU is originally a graphics card, it is born for the game and rendering, its core operating unit is shader, specifically used for pixel, vertex, graphics and other rendering.
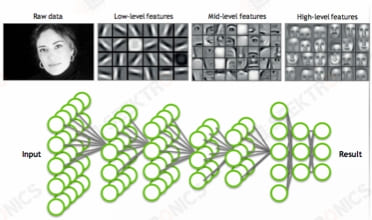
In 2006, NVidia introduced the Unified Computing Device Architecture (CUDA) and the corresponding G80 platform, which for the first time made the GPU programmable, allowing the GPU's core Streaming Processors (SPs) to have both pixel, vertex, and graphics rendering capabilities and general-purpose rendering capabilities. NVidia called it GPGPU (General Purpose GPU), which is the ambition of Godfather Huang to make GPUs capable of doing both games and rendering as well as general-purpose computing with high parallelism.
In 2006, the first generation GPGPU architecture G80
G80 has 16 groups of Streaming Processors (SPs), with 16 computing cores in each group of SPs, totaling 128 independent computing cores, with a single precision peak computing power of 330 Gflops, while the mainstream Core2 Duo CPUs only had 50 Gflops of processing power during the same period. More importantly, starting from the G80 architecture, GPUs began to support programmability, and all computationally intensive parallel tasks can be programmatically ported to run on the GPU.
CUDA's Programming Model
CUDA abstracts the GPU computational unit into three programming levels: Grids, Blocks and Threads. A CUDA kernel passes data and instructions to the GPU before execution, and uses several Grids during execution. Threads, the Threads of the last Block will be scheduled to a separate Streaming Processors for execution, and 16/32 Threads is called a Warp, Warp is the smallest unit of instruction scheduling on the GPU, a Warp will run on 16/32 compute cores at the same time.

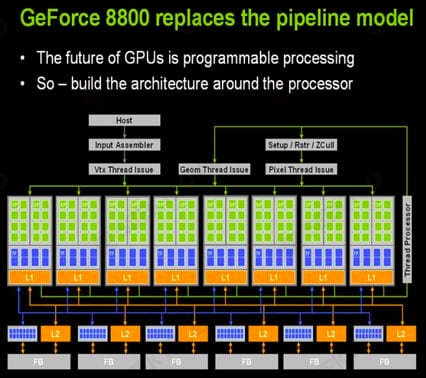
Performance growth far exceeds CPU strategy
Since the launch of the Tesla architecture in 2006, NVidia has continued to update its architecture and performance, successively launching Femi, Maxwell, Pascal and the latest Volta architecture, basically maintaining a two-year performance-doubling growth trend.
The performance acceleration ratio of the CPU, in single-precision computing power maintains a far ahead of the trend, and open the gap more and more.
Deep neural network + NVidia GPU set off a wave of artificial intelligence
Deep neural network + NVidia GPU has set off a wave of artificial intelligence in the industry. It must be said that this is just a by-product of the overall strategy of Old Huang, who did not expect that artificial intelligence, a branch of high-performance computing, would be so hot.
In 2011, Wu Enda, who was responsible for Google's brain, learned to recognize cats within a week by letting deep neural networks train pictures, and he used 12 GPUs instead of 2,000 CPUs, which was the first time in the world that a machine knew cats.
In 2015, Microsoft Research used GPU-accelerated deep neural networks to win several ImageNet competitions to beat human recognition accuracy, which was the first time that the recognition rate of machine vision beat the recognition rate of human eyes (5% error rate) and can be considered as an important milestone event in the history of artificial intelligence.
In 2016, AlphaGo, a robot developed by Google's Deepmind team, beat world Go champion professional ninth-degree player Lee Sedol 4-1 (AlphaGo used 50 GPUs for neural network training and 174 GPUs for go network), which triggered an uproar in the Go community, as Go has always been considered the pinnacle of human intellectual competition, and this can be seen as another major milestone event in the history of artificial intelligence.




-20x20-20x20.png)