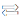The GPU is the "heart" of the graphics card, which is equivalent to the role of the CPU in the computer. It determines the grade and most of the performance of the graphics card, and it is also the difference between 2D and 3D graphics cards. 2D display chips mainly rely on the CPU's processing power when processing 3D images and special effects, known as "soft acceleration". The 3D display chip is the three-dimensional image and the special effects processing function is concentrated in the display chip, which is the so-called "hardware acceleration" function. The display chip is usually the largest chip (and the one with the most pins) on the display card. The GPU makes the graphics card less dependent on the CPU and does some of the work of the CPU, especially in 3D graphics processing. The core technologies used by GPU include hardware T&l, cubic environment material mapping and vertex mixing, texture compression and bump mapping, dual texture four-pixel 256-bit rendering engine and hardware T&L technology can be said to be the symbol of GPU.
Main function
Today, GPU is no longer limited to 3D graphics processing. The development of GPU general computing technology has attracted a lot of attention in the industry. It has been proved that GPU can provide tens of times or even hundreds of times the performance of CPU in floating point computation, parallel computation and other parts of the computation. Such a strong "new star" will inevitably make the CPU manufacturer leader Intel nervous about the future, NVIDIA and Intel are often locked in a war of words over which CPU or GPU is more important. GPU general computing standards currently include OPEN CL, CUDA, and ATI STREAM. Among them, OpenCL(full name Open Computing Language) is the first open, free standard for parallel programming for the general purpose of heterogeneous systems, as well as a unified programming environment. It is easy for software developers to write efficient and portable code for high-performance computing servers, desktop computing systems, and handheld devices and is widely applicable to multi-core processors (CPUs), graphics processors (GPUs), Cell architectures, digital signal processors (DSPS) and other parallel processors. In games, entertainment, scientific research, medical and other fields have broad development prospects, AMD-ATI, and NVIDIA products now support OPEN CL.NVIDIA company in 1999 when the release of GeForce 256 graphics processing chip first proposed the concept of GPU. Since then, the core of NV graphics cards has been called the GPU by this new name. The GPU makes the graphics card less dependent on the CPU and does some of the work of the CPU, especially in 3D graphics processing. The core technology of GPU is hardware T
Working principle
Simply put, GPU is a display chip that can support T&L(Transform and Lighting, polygon conversion and light source processing) from the hardware, because T&L is an important part of 3D rendering, its role is to calculate the 3D position of polygons and process dynamic lighting effects, also known as "geometry processing". A good T&L unit can provide detailed 3D objects and advanced light effects; However, in most PCS, most operations of T&L are processed by CPU (this is also called software T&L). Due to various tasks of CPU, besides T&L, CPU also has to do non-3D graphics processing such as memory management and input response, so the performance in actual computation will be greatly reduced. All too often, graphics cards are waiting for CPU data, which is far too fast for today's complex 3D games. Even if the CPU is operating at more than 1GHz or higher, it doesn't help much, as this is a problem caused by the PC's own design and has little to do with the speed of the CPU.
Differences between GPU and DSP
The GPU differs from the Digital Signal Processing (DSP) architecture in several major aspects. All of its calculations use floating-point algorithms, and there are currently no bit or integer arithmetic instructions. In addition, since Gpus are designed for image processing, the storage system is actually a two-dimensional segmented storage space, including a section number (from which the image is read) and two-dimensional address (X and Y coordinates in the image). In addition, there are no indirect write instructions. The output write address is determined by the raster processor and cannot be changed by the program. This is a great challenge for algorithms that are naturally distributed in memory. Finally, communication between the processing of different shards is not allowed. In effect, the shard handler is a SIMD data-parallel execution unit that executes code independently among all the shards.
Despite these constraints, Gpus can efficiently perform a wide range of operations, from linear algebra and signal processing to numerical simulation. While the concept is simple, it can still confuse new users when computing with Gpus, which requires specialized graphics knowledge. In this case, some software tools can help. Two advanced shading languages, CG and HLSL, allow users to write C-like code that is then compiled into shard assembly language. Brook is a high-level language designed for GPU computing and requires no knowledge of graphics. So it's a good starting point for people who are using the GPU for the first time. Brook is an extension of the C language that incorporates simple data parallel programming constructs that can be mapped directly to the GPU. The data that is stored and manipulated by the GPU is visualized as a "stream," similar to an array in standard C. A Kernel is a function that operates on a stream. Calling a core function on a series of input streams means that an implicit loop is implemented on the flow elements, that is, the core body is called on each flow element. Brook also provides a reduction mechanism, such as a sum, maximum, or product calculation for all elements in a stream. Brook also completely hides all the details of the graphics API and virtualizes parts of the GPU that many users are unfamiliar with, such as the two-dimensional memory system. Applications written in Brook include linear algebra subprograms, fast Fourier transform, ray tracing, and image processing. Using ATI's X800XT and Nvidia's GeForce 6800 Ultra Gpus, many of these applications are up to seven times faster with the same cache, SSE assimilation-optimized Pentium 4 execution.
Users interested in GPU computing struggle to map algorithms to graphic base elements. The advent of high-level programming languages such as Brook made it easy for novice programmers to grasp the performance benefits of Gpus. The ease of accessing GPU computing capabilities also means that the evolution of the GPU will continue, not just as a rendering engine, but as the primary computing engine for personal computers.
What's the difference between a GPU and CPU?
To explain the difference, it's important to understand the similarities: both have buses and external connections, their own caching systems, and numeric and logical computing units. In short, both are designed to accomplish computing tasks.
The difference between the two lies in the on-chip cache system and the structure of the digital logic unit: although the CPU has multiple cores, but the total number does not exceed two digits, each core has a large enough cache and enough digital and logic units, and there is a lot of auxiliary hardware to speed up branch judgment and even more complex logic judgment; Gpus have far more cores than cpus and are known as crowd cores (NVIDIA Fermi has 512 cores). The cache size per core is relatively small, and the number logic units are few and simple (Gpus have always been weaker than cpus in floating-point calculations initially). As a result, cpus are good at processing complex computing steps and complex data dependencies, such as distributed computing, data compression, artificial intelligence, physical simulation, and many, many other computing tasks. Due to historical reasons, GPU was produced for video games (until now, its main driving force is still the growing video game market). A kind of operation that often appears in 3D games is to carry out the same operation on massive data, such as: carry out the same coordinate transformation for each vertex, calculate the color value according to the same lighting model for each vertex. The GPU's multi-core architecture is very suitable for sending the same instruction stream to multiple cores in parallel and executing with different input data. Around 2003-2004, experts outside of graphics began to notice the unusual computing capabilities of Gpus and began to experiment with using Gpus for general-purpose computing (known as GPGpus). After NVIDIA released CUDA, and companies like AMD and Apple released OpenCL, Gpus began to be widely used in general-purpose computing, including numerical analysis, mass data processing (sorting, Map-Reduce, etc.), financial analysis, and so on.
In short, when programmers write programs for cpus, they tend to use complex logical structures to optimize algorithms and reduce Latency for computing tasks. When programmers write programs for Gpus, they take advantage of their ability to handle large amounts of data and mask Latency by improving the total data Throughput (Throughput). Currently, the distinction between cpus and Gpus is narrowing, as Gpus have also come a long way in handling irregular tasks and inter-thread communication. In addition, power consumption is more of a problem for Gpus than cpus.
In general, the difference between Gpus and cpus is a big topic.
Comparison of the floating-point computing power of CPU and GPU
CPU-GPU floating-point arithmetic comparison
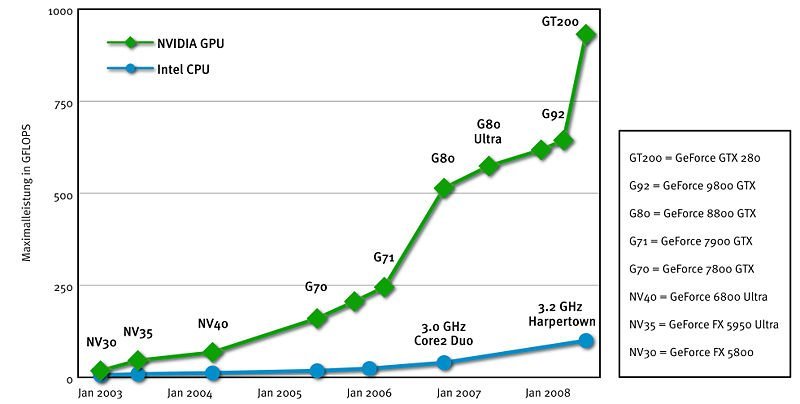
Nvidia's CUDA documentation gives this picture: ALU stands for "arithmetic logic Unit
(ALU is the "Arithmetic logic unit".)
The computing part of CPU and GPU is ALU. As shown in the figure, most of the chip area of GPU is ALU, and it is ALU in a super-large array arrangement. All of these AlUs can run in parallel, so floating-point calculations are high-speed.
In contrast, most of the CPU area needs to be given to the control unit and Cache, because the CPU is responsible for the control of the entire computer, not as simple as the GPU.
As a result, the GPU's program control capabilities are not as strong as the CPU's, and older CUDA programs like recursion don't work (they do on newer devices).
The CPU does not increase floating-point computing speed, but because it is not particularly necessary. Our normal desktop applications don't require any special floating point computing power at all. At the same time, the GPU is already available, so if you need floating-point computing, you can use it.
First, can a CPU remove cache like a GPU does? No. The GPU can eliminate cache because of two key factors: data specificity (high alignment, pipeline processing, does not conform to the localization assumption, rarely write back data) and high speed bus. For the latter problem, cpus are hampered by outdated data bus standards, which in theory can be changed. The former problem is theoretically difficult to solve. Because cpus want to provide versatility, they cannot limit the kinds of data they process. This is why the GPGPU will never replace the CPU.
Second, can the CPU add a lot of cores? No. First, the cache takes up space. Second, the CPU increases the complexity of each core in order to maintain cache consistency. Also, the CPU requires complex optimizations (branch prediction, out-of-order execution, and vectorization instructions and long pipelines that partially mimic the GPU) to make better use of the cache and handle data that is unaligned and requires a lot of write-back. Therefore, the complexity of a CPU core is much higher than that of a GPU, thus the cost is higher (not that the cost of etching is higher, but that complexity reduces the rate of production, so the cost is higher in the end). So cpus can't add cores like Gpus can.
As for control power, the status quo of the GPU is worse than the CPU, but that's not the fundamental problem. Control such as recursion, which is not appropriate for highly aligned and pipeline-processed data, is essentially a data problem.
Regardless of instruction sets, caches, and optimizations, just looking at the main frequency shows that a single core floating point computing power of a CPU is much more powerful than a GPU.
The highest GPU core is around 1Ghz, while the CPU core is 3-4 GHZ. The difference is that cpus have at most a dozen cores and Gpus have hundreds or thousands of cores.
Not to mention the more comprehensive CPU core instruction set, the GPU core basically only has SIMD instructions (because the GPU is mainly used for graphics processing, vector operations are far more than scalar operations. And for the CPU, one more set of instruction computing unit, is the cost of several cores; That's the cost of hundreds or thousands of additional cores for the GPU.)
The CPU processes scalar multiplication only once with a scalar multiplication instruction, whereas the GPU converts the scalar first into a vector and then uses a SIMD instruction.
Each core of the CPU has an independent cache, and basically all cores of the GPU share a cache (GPU is mainly used for graphics rendering, and all cores execute the same instruction and obtain the same data. The CPU mainly performs multiple serial tasks, and each core can handle different tasks and obtain different data from different places.) So CPU single core performance in seconds GPU single core ten streets.
Each CPU core has independent optimizations, branch prediction, out-of-order execution, and the like.
GPU out-of-order execution can exist because all cores do the same thing and can share a single instruction without the need for separate out-of-order execution (although it usually doesn't, since this functionality can be implemented directly into the compiler). Because the GPU development language is few, basically only GLSL and HLSL, the compiler is developed by the manufacturer. Unlike cpus, where development languages are numerous, compilers are numerous, and instruction sets are vastly different, dynamic out-of-order optimization is urgently needed.
GPU branch prediction is definitely not available. In terms of cost, branch prediction cannot be shared. The cost of one more branch prediction for each core is too high. The point is that you don't need to. GPU programs are generally short and could have been loaded into the cache altogether; Secondly, branch prediction is meaningless for tasks processed by GPU.
The strong point of Gpus is that they are better at parallel computing than cpus (the parallel computing of multiple different tasks is not adequate for Gpus to handle parallel computing of a single parallel task), not that they are better at floating-point computing. (I don't know who started this rumor, but emphasize floating-point arithmetic. Most older Gpus don't even have integer arithmetic, if not floating-point arithmetic, because there are no integer instructions. The GPU was originally designed to speed up graphics rendering, which is basically floating-point arithmetic. Therefore, the GPU core SIMD instruction only has floating point instruction, no integer instruction; The new GPU is not only used for graphics rendering, but also wants to be generalized to general computing, which is called GPGPU, so it started to add integer arithmetic support.
Gpus are designed entirely for parallel computing.
Only parallel operations with no data dependencies are fast on the GPU.
Let's take a simple example
The core of the CPU is like a master of mental arithmetic and can perform four operations 100 times a minute
The core of a GPU is that the average person can perform four operations 10 times a minute
But you have 10 good mental arithmetic players working together to do 10,000 quadratic operations and 1,000 normal people working together to do 10,000 quadratic operations
Who do you think finished it faster?
A thousand ordinary people, of course
(It takes 10 good mental calculators 10 seconds each to do 1000. It takes 1000 ordinary people 1 second each to do 10.)
But if 10,000 of these four operations are dependent then the condition of the next problem depends on the result of the last problem
Who do you think is the fastest?
Of course, it's a good mental calculator because once you have this kind of strong dependence you can only do it with 10 people and 1,000 people and you can't do it faster than one person
(It takes 100 seconds for a good mental calculator and 1,000 seconds for an average person)




-20x20-20x20.png)